
Most teams have done the localization work before. Your translation team validated hundreds of segments last quarter. Marketing refined glossaries for three product launches. Legal-approved terminology across compliance documents. That work sits unused when you start a new AI translation project.
The problem is that companies treat each localization initiative as a blank slate, asking AI to ignore perfectly good reference material already sitting in their TMS. The cost shows up as inconsistent brand voice, duplicate effort, and translations that contradict approved terminology.
The fix is already in your TMS. Translation memories capture approved phrasing. Glossaries enforce consistent terminology. Style guides (maintained by your team) preserve brand voice across markets. AI draws on the first two directly; the third shapes how you brief and review translations. Together, they mean better output without rebuilding your knowledge base on every project.
This guide covers how to identify translation assets worth reusing, structure them for AI, and build workflows where human judgment trains AI rather than constantly correcting it.
TL;DR
|
What counts as a translation asset, and why AI needs them
Translation assets are structured records of previous localization decisions. They include:
- Translation memories that store sentence-level matches between source and target languages.
- Glossaries that define approved terminology for products and features.
- Style guides that specify tone, formatting rules, and cultural conventions; maintained by your team as a reference for reviewers.
- QA checklists that document what passed review in prior projects.

These assets represent accumulated human expertise. When a translator validates that “checkout” translates to “caisse” in French Canadian retail contexts, that decision has value beyond the single document. When legal counsel approves specific phrasing for a compliance term, that approval should inform future uses.
Of these, translation memories and glossaries are the two you can feed directly into AI translation tools like Lara Translate. Style guides work differently — they guide the humans reviewing AI output, not the AI itself. That distinction matters when you are deciding what to build and where to invest time.
Treating these decisions as reusable data rather than one-time outputs is the whole point. Without structured reuse, AI translation starts from general language patterns. With proper asset integration, AI starts from your validated terminology, approved style, and proven translations.
The quality difference is consistency. Generic AI might translate “subscription tier” differently across documents. AI working from your glossary uses the exact term your marketing validated, your documentation references, and your customers recognize.
How to identify and audit your existing translation assets
Start by locating where previous translation work actually lives. Most organizations have assets scattered across TMS platforms, shared drives, project folders, and translator files.
The audit has three steps: find what you have, assess what is worth keeping, and decide what is ready to use.
Finding translation assets
Check your TMS for translation memory segments. Search shared drives for glossary spreadsheets. Review project documentation for style guides and QA checklists. Ask translation vendors what records they maintain. Many teams find valuable assets in archived project folders from past campaigns or legacy systems.
Assessing quality
High-value assets include approved translations reviewed by subject matter experts, glossaries validated by legal or compliance teams, style guides that reflect current brand voice, and QA records from rigorous review cycles.
Low-value assets include unvalidated machine translation output, glossaries containing outdated terminology, style guides from prior brand identities, and translation memories that mix approved and draft content.
Determining reusability
Match asset domain, language pair, and quality level to current needs. A translation memory from technical documentation may not help marketing content. A glossary built for financial services may not transfer to healthcare.
Record what you find: asset type, languages covered, approximate size, quality level, last update date. This becomes your starting point for building a systematic asset-driven localization program rather than an ad hoc one.
How translation memory reduces rework and keeps terminology consistent
Translation memory systems store sentence pairs showing how your organization previously translated specific content. When new text matches or resembles previous translations, the TM suggests the approved version.
![]()
Using translation memory and glossaries together covers different ground and helps maintain both consistency and speed. Exact matches require no new translation work. Fuzzy matches (typically 70–99% similar) need minor adjustments. Even partial matches provide context that improves quality.
Using TM effectively requires proper setup: clean your TM by removing duplicate entries, filtering unvalidated segments, standardizing formatting tags, and organizing by content domain. A translation memory that mixes marketing prose with technical jargon produces worse results than separate, domain-specific memories.
On paid Lara Translate plans, TMs are linked to your account by the Support team. You can send TMX files to support@laratranslate.com, and they will handle the upload and setup. Once linked, you can select or deselect any TM directly from the interface before translating. For a walkthrough, see Using Translation Memories in Lara’s UI.
You can also build a personal translation memory from scratch. Edit any text translation output manually, then click Add to Memory. Lara saves the corrected segment to a Personal Memory that applies automatically to future translations. See Add to Memory: Build your own translation memory for how it works.
Monitor TM effectiveness
Track match rates (the percentage of new content with TM matches), review time reductions, and consistency improvements. These numbers show which content types benefit most from content reuse and where expanding TM coverage would help most.
TM maintenance matters over time. Archive outdated translations, add newly validated segments, remove deprecated terminology, and split overgrown databases into focused collections.
Using glossaries to enforce terminology standards
Glossaries define approved translations for critical vocabulary. Unlike translation memory, which stores full sentences, glossaries focus on specific terms: product names, feature labels, technical jargon, legal phrases.
The business case is risk reduction. Inconsistent terminology confuses customers, complicates support, and creates legal exposure. When your English documentation calls something “user dashboard” but your French help center uses three different terms, users cannot find answers.
Translation memory and glossaries solve different problems. TM handles recurring sentences. Glossaries handle critical terms that must translate exactly the same way every time.
Build effective glossaries
Bring in stakeholders from across the organization: marketing defines brand terms and product names, legal validates compliance terminology, customer support identifies the terms users actually search for, and technical teams document feature names and UI labels.
Structure glossaries with clear fields: source term, target translations per language, part of speech, usage context, approval status. Add usage notes explaining when a term applies and which alternatives to avoid.
In Lara Translate, glossaries are uploaded as CSV files and are unidirectional and case-sensitive — they apply from source to target language only, not the reverse. Pro plan users can create one glossary directly from the UI; Team plan users can create and manage unlimited glossaries and share them across the team. See How glossaries work in Lara for setup instructions.
Keep glossaries current
Add new terms when products launch. Revise translations when brand voice shifts. Archive deprecated terms when features are retired.
Style guides: a reference for your reviewers, not an AI input
Style guides define how your organization communicates beyond word choices. They specify tone (formal vs casual), formatting conventions (dates, numbers, capitalization), voice (active vs passive), and cultural adaptation rules.
Unlike translation memories and glossaries, style guides are not something you upload to an AI translation tool. They work differently: reviewers consult them when validating AI output, and they inform how you brief translators on edge cases. That makes them an essential part of your localization program, just at a different layer than TM and glossary.
In Lara Translate, tone is handled through Translation Styles. Faithful prioritizes accuracy for technical and legal content. Fluid balances accuracy with natural phrasing. Creative adapts messaging for marketing while maintaining expressive impact. Selecting the right style is the quickest way to align AI output with your content’s register before reviewers apply finer judgment from your internal style guide.

For teams working on marketing content specifically, maintaining brand voice across languages requires strategies beyond style selection alone.
Effective style guides use concrete examples
Instead of “maintain friendly tone,” show two versions — one too formal, one appropriately friendly — with annotations explaining the difference. Instead of “adapt cultural references,” list specific examples: “Replace American football metaphors with football (soccer) in European markets.”
Document formatting rules that vary by language and region. Some languages capitalize differently, format addresses distinctly, or structure dates in region-specific ways. Specify these conventions explicitly.
Address topics that require localization awareness. Note which humor styles do not translate well, which product claims need regulatory adjustment, which imagery carries different cultural associations.
Structure for practical use
Organize style guides with sections for general voice and tone, language-specific guidelines, content type variations (marketing vs documentation vs legal), and practices to avoid. Make guidelines searchable and easy to reference mid-project — your reviewers will reach for them during QA, not before.
Content reuse strategies that make previous translation work pay off
Content reuse in localization means identifying components that appear across assets and translating them once. Common reusable components include product descriptions used across websites and catalogs, legal boilerplate appearing in multiple agreements, support responses for frequent questions, and UI strings shared across applications.
These gains add up. If you translate a product description once and reuse it across website, email campaigns, and social media in fifteen languages, you have avoided translating that content 45 times.
Identify reusable content
Audit your content inventory for duplicated text, near-duplicates with minor variations, modular components that recombine in different ways, and templates with fixed structures and variable content.
Structure for reuse
Create content libraries where translated components are tagged, searchable, and version-controlled. Give things consistent names so people can actually find them. Build templates that combine reusable blocks with spaces for custom content.
The challenge is managing variation. A product description for your website might need adjustment for an email campaign. The practical approach is flexible modules with approved baseline translations and documented variation guidelines.
Building a hybrid AI-human translation workflow
The most effective approach combines AI speed with human expertise. AI handles volume and generates first drafts informed by your translation assets. Humans focus on validation, cultural adaptation, and cases where context requires judgment.

Categorize content based on risk and complexity
Low-risk content includes product specifications, technical documentation with clear terminology, and internal communications. High-risk content includes marketing headlines, legal agreements, customer-facing support, and anything touching regulatory compliance. This categorization determines how much human review each content type needs.
Design smart routing
Set systems to auto-translate when confidence scores exceed thresholds, TM matches are exact or near-exact, all terms exist in validated glossaries, and the content type is low-risk. Route to human reviewers when confidence scores are low, no TM matches exist, new terminology appears, or the content type is high-risk.
Give reviewers a clear role
Reviewers validate AI output against your style guide, check cultural appropriateness, verify that glossary terms apply correctly in context, and assess whether the translation achieves its intended purpose. They also improve the system: adding validated translations to memory, expanding glossaries with newly approved terms, refining style guide examples, and documenting edge cases.
Build feedback loops
When reviewers change AI output, capture those changes as new TM segments. When they add glossary entries, make them immediately available to subsequent translations. The system should get better with every review cycle, not reset.
Track what matters
Measure translation speed per language pair, human review time per content type, consistency scores across similar content, and business outcomes like reduced support tickets from translation issues.
Try Lara Translate in your own workflow
Test Lara Translate on a real client text and see how it handles your terminology, context, and formatting.
How Lara Translate works with existing translation assets
Lara Translate supports translation memories and glossaries, so AI translation can draw on previous human expertise rather than starting from scratch.
Lara analyzes entire documents rather than isolated sentences, which helps maintain consistent terminology and tone across long-form content. This context-aware approach is particularly useful when working with translation memories and glossaries, as Lara can assess whether a TM suggestion fits the broader document context before applying it.
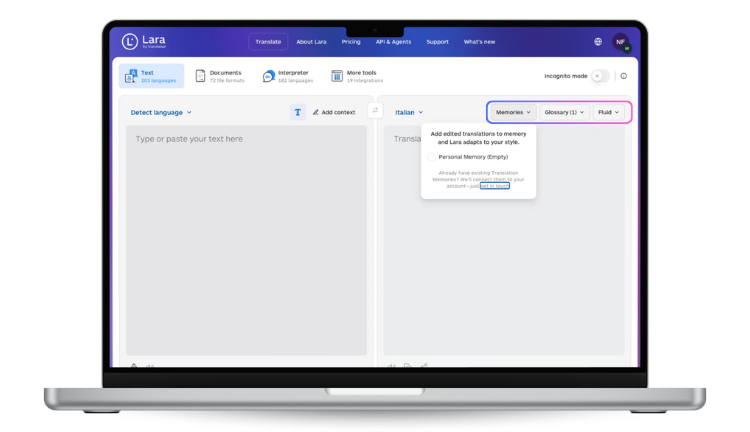
Three translation styles for different content needs
Translation Styles are Lara’s built-in mechanism for matching tone to content type — the closest equivalent to applying a style guide at the AI layer. Faithful prioritizes accuracy for technical and legal content. Fluid balances accuracy with natural phrasing for business communications. Creative adapts messaging for marketing content while maintaining expressive impact. Your internal style guide then guides reviewers on anything finer-grained.
Speed for large content volumes
With 99% of translations completed in 1.2 seconds, teams can translate updated content in near real-time rather than batching work into periodic cycles.
Format and integration support
Lara Translate supports over 70 file formats and provides API access for custom integrations. Teams can continue working in familiar TMS interfaces while using Lara’s translation capabilities.
Security and compliance
GDPR compliance and Incognito Mode address concerns when processing proprietary or regulated material through AI translation systems.
Measuring success and optimizing your asset-driven localization program
Track metrics to assess whether AI translation with existing assets is delivering the results you expected.
Efficiency metrics
Translation memory match rates show what percentage of new content draws on existing translations. Review time per word compares human effort before and after asset integration. Localization cost per language pair tracks whether efficiency gains translate to budget reductions.
Quality metrics
Customer feedback on translated content, support ticket volumes related to language issues, and engagement metrics for localized material compared to source language baselines all tell you whether quality is actually improving.
Maintenance cycles
Run quarterly glossary reviews to add new terms and archive outdated ones. Do annual TM cleanups to remove duplicates and consolidate fragmented databases. Update style guides when brand voice evolves or market feedback suggests adjustments — and make sure reviewers know when the reference has changed.
Document what you learn
Record which content types benefit most from TM reuse, which terminology areas need more comprehensive glossaries, where style guides need clearer examples, and which workflows balance AI efficiency with human oversight most effectively.
Expand from what works
Start with your highest-volume, most repeatable content in priority markets. Once you have proof the approach works, extend it to additional content types and languages.
Have a valuable tool, resource, or insight that could enhance one of our articles? Submit your suggestion
We’ll review it and consider it for inclusion to enrich our content for our readers.
FAQs
What is the difference between translation memory and a glossary?
Translation memory stores sentence pairs showing how you previously translated content in context. Glossaries store approved translations for specific terms — product names, features, legal phrases — that must stay consistent everywhere. You need both: TM for context and recurring sentences, glossaries for critical terminology. See What Are Translation Memories? and How glossaries work in Lara for more detail.
Can AI translation tools learn from my company’s previous translations?
Yes. Modern AI platforms accept translation memories and glossaries as input. Lara draws on your approved translations and applies your validated terminology. In Lara Translate, you upload TMX files for translation memory and CSV files for glossaries. Both are applied at translation time to shape output — they are not used to retrain the underlying model, which matters for confidentiality. Style guides are not uploadable to Lara; they function as a reference your reviewers use during QA.
How do I know if my existing translation assets are good enough to reuse?
Check three things: validation status (reviewed and approved by subject matter experts), relevance (matches current content and audiences), and recency (reflects current products and brand voice). Skip unvalidated machine output, outdated terminology, and anything from before a major brand change.
What content types benefit most from translation asset reuse?
Content with recurring elements: product documentation with standardized descriptions, help center articles, legal template language, marketing emails with consistent structures, and repeated UI strings. Technical documentation has high TM match rates because concepts repeat across products and versions.
How often should I update translation memories and glossaries?
Update glossaries immediately when launching products or when legal feedback requires terminology changes. Add validated translations to TM continuously as they receive approval. Run quarterly glossary reviews and annual TM cleanups to remove duplicates and keep databases manageable. You can build your personal memory incrementally using Lara’s Add to Memory feature.
This article is about
- Using translation memories and glossaries to improve AI translation quality and consistency across multilingual content
- Using translation memory and glossaries to reduce duplicate translation work and enforce approved terminology standards
- Identifying and auditing existing translation assets to determine which previous human work is worth reusing
- Building hybrid AI-human translation workflows where AI handles volume using your assets while humans apply style guide judgment during review
- Measuring success through match rates, consistency scores, and quality metrics that show whether asset-driven localization is working


