
La maggior parte delle API di traduzione offre una cosa sola: una traduzione. Nessun contesto, nessun controllo della terminologia, nessuna preferenza di stile. Il risultato è quello che il modello produce per default, il che va bene per un’attività occasionale, ma diventa un serio problema quando il tuo prodotto serve utenti in più lingue ogni giorno e su larga scala.
Il divario tra una traduzione tecnicamente corretta e una che puoi effettivamente pubblicare non è un problema di modello. È un problema di configurazione. Ciò che passi all’API determina ciò che ottieni. E la maggior parte delle API di MT generiche non ti dà modo di passare nulla di significativo.
Questo articolo spiega cosa sono le API di traduzione adattiva, cosa rendono possibile per i team di prodotto, e come Kanpla, una piattaforma di ristorazione collettiva che serve oltre 4.500 location, ha usato l’API di Lara Translate per sostituire un setup multilingue frammentato e di bassa qualità con un layer di localizzazione completamente automatizzato e guidato dal contesto, che ha elaborato 149,4 milioni di caratteri in 90 giorni.
TL;DR
|
Come fanno le startup a scalare la localizzazione con l’IA? Collegano un’API di traduzione adattiva che accetta istruzioni contestuali, glossari e memorie di traduzione a ogni chiamata, poi automatizzano il trigger in modo che la traduzione avvenga senza intervento umano. Kanpla, una piattaforma SaaS per la ristorazione collettiva, ha implementato esattamente questo con l’API di Lara Translate. Ha raggiunto una copertura multilingue completa dell’intera app, eliminato le voci di prodotto duplicate per lingua e ridotto il costo per carattere grazie al caching integrato — il tutto con zero passaggi di revisione manuale nella pipeline.
Cos’è un’API di traduzione adattiva?
Un’API di traduzione automatica standard accetta una stringa e restituisce una traduzione. Questo è tutto. Non c’è modo di indicarle chi è il destinatario, qual è il dominio, quali termini devono essere preservati o quale registro deve avere l’output. Ottieni ciò che il modello sa per default.
Un’API di traduzione adattiva funziona diversamente. Ogni chiamata può portare parametri che modellano l’output prima che il modello inizi: istruzioni contestuali, uno stile preferito, un glossario di termini da rispettare e voci di memoria di traduzione che garantiscono coerenza rispetto alle traduzioni approvate in precedenza.
Lara Translate ha costruito questo modello nella sua API fin dall’inizio. Ecco cosa espone a livello di API.
Stili di traduzione
Puoi scegliere tra Fedele (precisione tecnica), Fluido (uso generale naturale) o Creativo (copy marketing e brand) per ogni singola chiamata. Una clausola legale e una notifica push non dovrebbero essere tradotte allo stesso modo. Con la selezione dello stile a livello di API, non devono esserlo.

Istruzioni contestuali
Passi un’istruzione in linguaggio naturale insieme al testo — qualcosa come “registro formale, rivolto a responsabili acquisti in Francia” o “tono colloquiale, stringa di UI mobile, massimo 40 caratteri.” Il modello si adatta di conseguenza. La maggior parte delle API non è in grado di farlo. La stessa stringa sorgente può produrre output significativamente diversi a seconda del contesto che fornisci, senza alcun riaddestramento del modello. Consulta i casi d’uso comuni delle istruzioni contestuali nella knowledge base di Lara Translate.
Glossari
La tua terminologia di brand viaggia con ogni chiamata. Nomi di prodotto, termini legali, etichette UI che non devono cambiare. Definiscili una volta, e l’API li applica in ogni output. Come funzionano i glossari in Lara Translate copre la configurazione in dettaglio.
Memorie di traduzione
Le traduzioni approvate in precedenza vengono memorizzate e consultate a ogni chiamata. Più usi l’API, più l’output diventa coerente, perché si ancora alla tua storia, non solo ai default del modello. Le memorie di traduzione sono disponibili nativamente nella piattaforma e funzionano su tutte le chiamate API. Consulta Modalità Apprendimento vs. Modalità Incognito per capire come funzionano la memorizzazione e la memoria.
Tipi di contenuto
Oltre al testo, l’API di Lara Translate gestisce documenti (70+ formati tra cui DOCX, PDF, PPTX, XLIFF, PO, SRT e JSON), immagini tramite OCR e file audio tramite una pipeline asincrona di upload e polling. Il layout viene preservato nella traduzione di documenti. I formati di localizzazione come XLIFF e PO ricevono una gestione struttura-safe: vengono modificate solo le stringhe traducibili, mentre struttura del file, attributi, ID e metadati rimangono invariati.
Per i team che già usano Trados Studio, MemoQ o MateCat, le integrazioni native con i plugin collegano l’API direttamente a quei flussi di lavoro CAT senza export e re-import manuali.
Scopri l’API di traduzione adattiva in azione
Collega il tuo prodotto a una traduzione contestuale e con glossari applicati in 200+ lingue. È disponibile un piano gratuito senza carta di credito.
Come Kanpla ha usato l’API di Lara Translate per localizzare un prodotto SaaS completo
 Kanpla è una piattaforma per la ristorazione collettiva. Il loro software connette cucine, ospiti e dati operativi in oltre 4.500 location, servendo clienti come Compass Group, Aramark e BaxterStorey. Il prodotto copre punto vendita, ordini, menu, chioschi, hospitality, programmi fedeltà e comunicazioni in-app — il che significa che quasi ogni testo visibile all’utente nell’app è qualcosa che un utente legge effettivamente per prendere una decisione: cosa ordinare, cosa contiene allergeni, quanti punti fedeltà ha accumulato.
Kanpla è una piattaforma per la ristorazione collettiva. Il loro software connette cucine, ospiti e dati operativi in oltre 4.500 location, servendo clienti come Compass Group, Aramark e BaxterStorey. Il prodotto copre punto vendita, ordini, menu, chioschi, hospitality, programmi fedeltà e comunicazioni in-app — il che significa che quasi ogni testo visibile all’utente nell’app è qualcosa che un utente legge effettivamente per prendere una decisione: cosa ordinare, cosa contiene allergeni, quanti punti fedeltà ha accumulato.
Quando i tuoi utenti sono distribuiti in più paesi e hanno background linguistici diversi, non si tratta di un problema di traduzione. È un problema di accessibilità. Ed è un problema che Kanpla stava gestendo in modo imperfetto.
Com’era la situazione prima
Prima di Lara Translate, Kanpla supportava più di 15 lingue. La copertura era superficiale. La traduzione si applicava solo ai menu, e anche in quel caso gli utenti dovevano attivarla manualmente, sezione per sezione. L’esperienza era frammentata: gli utenti navigavano l’app in una lingua e traducevano le singole parti senza che venisse passata alcuna indicazione contestuale al motore sottostante.
Le conseguenze si vedevano nell’output. Senza contesto, l’API non aveva modo di sapere cosa stava traducendo né per chi. Una voce di prodotto contenente le parole “Soy milk” tornava come “I am milk” (Sono latte). Un ingrediente descritto come “white beans” veniva tradotto come “white prayers” (preghiere bianche). In una piattaforma alimentare dove la precisione sugli allergeni è fondamentale, questo tipo di errore non si limita a fare brutta figura. Crea seri problemi di usabilità e fiducia.
L’integrazione: due giorni fino al proof of concept
Kanpla ha integrato l’API di Lara Translate e aveva un proof of concept funzionante in due giorni. La documentazione ha reso tutto semplice. La scelta di Lara Translate è ricaduta sulla specializzazione: è costruita specificamente per la traduzione, e questo si vedeva nel design del prodotto e nella reattività del team fin dal primo contatto.
L’integrazione è invisibile all’utente. Quando la lingua usata da un ristorante per creare i contenuti non corrisponde alla lingua preferita dell’utente finale (dedotta dalle impostazioni del dispositivo, dalle preferenze del browser o dalla selezione esplicita nell’app), l’app mostra un banner che offre di attivare la traduzione. Una volta accettato, le traduzioni vengono applicate istantaneamente all’intero prodotto. Nessun processo pagina per pagina. Nessun passaggio manuale da nessuna delle due parti.
La copertura si estende ora a ogni elemento visibile all’utente: schermata home, menu, elenco prodotti, impostazioni, dati nutrizionali, informazioni sulla CO2, etichette allergeni, pop-up, notifiche, banner e messaggi in-app.
Come le istruzioni contestuali hanno risolto il problema della qualità
Gli errori “I am milk” e “white prayers” derivavano dall’invio di stringhe grezze senza contesto. Kanpla ha risolto il problema allegando informazioni contestuali ricche a ogni richiesta API. Diverse sezioni dell’app portano contesti diversi. Una “stamp card,” ad esempio, viene contrassegnata come funzionalità di un programma fedeltà piuttosto che come oggetto fisico. I campi nutrizionali vengono taggati di conseguenza. Il modello riceve informazioni sufficienti per tradurre correttamente fin dalla prima volta.
I glossari personalizzati garantiscono una terminologia coerente sull’intera piattaforma. Quella combinazione — istruzioni contestuali per richiesta più termini del glossario applicati — ha eliminato la necessità di un passaggio di revisione manuale. Il flusso di lavoro è completamente automatizzato end-to-end.
Dietro le quinte, Kanpla utilizza anche un layer di caching. Una volta tradotta una stringa, il risultato viene memorizzato e riutilizzato nelle chiamate successive, evitando richieste API ridondanti. Questo mantiene i tempi di risposta rapidi e riduce il costo per carattere ad alto volume. Vale la pena configurarlo subito: alla scala di Kanpla, i risparmi si accumulano rapidamente.
I numeri
![]()
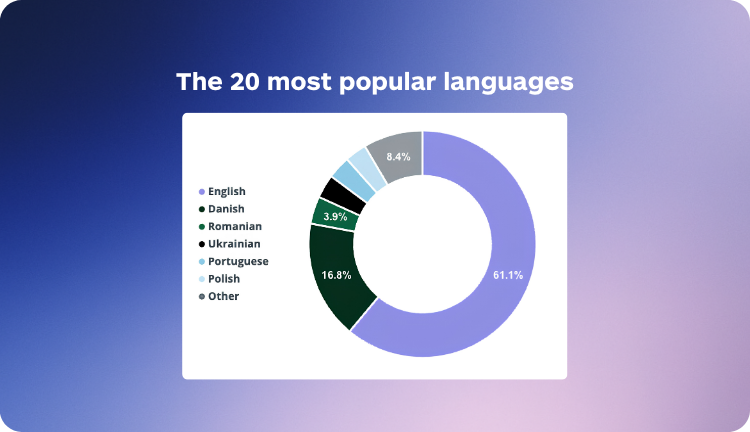
Negli ultimi 90 giorni, Lara Translate ha elaborato 149,4 milioni di caratteri per Kanpla. Le lingue con maggiore volume sono inglese, danese, rumeno, portoghese, ucraino e polacco, rispecchiando la reale composizione demografica degli utenti che accedono alla piattaforma nelle varie location.
| Metrica | Prima | Dopo |
|---|---|---|
| Lingue supportate | 15 (copertura superficiale) | 32+, qualità superiore |
| Ambito della traduzione | Solo menu, attivazione manuale | Intera app, automatica |
| Contesto per chiamata | Nessuno | Contesto per sezione + glossari |
| Revisione manuale | Sì | Nessuna |
| Volume (ultimi 90 giorni) | 0 (traduzione solo della piattaforma) | 149,4 milioni di caratteri |
Il cambiamento operativo più importante per i clienti enterprise
L’impatto più significativo a monte ha riguardato il modo in cui i partner enterprise gestiscono i dati di prodotto. In precedenza, i grandi clienti che gestivano centinaia di location mantenevano spesso voci duplicate per lingua. Una singola voce di menu poteva esistere come due record separati — uno in inglese e uno in danese. Quella duplicazione significava doppia manutenzione, doppio rischio di incoerenza e doppio overhead ogni volta che un contenuto cambiava.
 “Lara Translate ha reso molto più facile per noi scalare la localizzazione senza sacrificare velocità o esperienza utente. È ora integrata correttamente nel prodotto, il che ci ha aiutato a creare un’esperienza più fluida e accessibile per gli utenti man mano che cresciamo. Stiamo ora estendendo questo ad altri punti di contatto, tra cui segnaletica digitale, stampa e chioschi. Il prodotto è solido, il team capisce le nostre esigenze, e questo ha reso facile muoversi velocemente senza che la qualità scendesse.”
“Lara Translate ha reso molto più facile per noi scalare la localizzazione senza sacrificare velocità o esperienza utente. È ora integrata correttamente nel prodotto, il che ci ha aiutato a creare un’esperienza più fluida e accessibile per gli utenti man mano che cresciamo. Stiamo ora estendendo questo ad altri punti di contatto, tra cui segnaletica digitale, stampa e chioschi. Il prodotto è solido, il team capisce le nostre esigenze, e questo ha reso facile muoversi velocemente senza che la qualità scendesse.”
— Toby Bonnett, VP of Product, Kanpla
Con la traduzione gestita dinamicamente tramite API, sono passati a un modello a voce singola. Un record di prodotto. Un’unica fonte di verità. La traduzione avviene al momento del rendering, non al momento dell’inserimento dei dati. Meno overhead, meno errori, operazioni più semplici.
Dal lato utenti, il feedback è stato diretto. Kanpla ha ricevuto messaggi da utenti che finalmente riuscivano a leggere i menu che prima non capivano. Non si tratta di un miglioramento marginale dell’UX. Per una piattaforma il cui intero valore consiste nel connettere gli ospiti alle informazioni sul cibo, essere leggibili nella lingua dell’utente è il prodotto stesso.
Costruisci il tuo layer di localizzazione nel modo giusto
Collega l’API di Lara Translate al tuo flusso di lavoro. Contestuale, con glossari applicati e gratuita per iniziare.
Cosa i team di prodotto dovrebbero imparare da questo
Il caso Kanpla non è eccezionale. È un esempio nitido di cosa succede quando un team di prodotto smette di trattare la traduzione come una chiamata API una tantum e inizia a trattarla come un sistema configurabile.
Il modello che hanno costruito è replicabile. Collega l’API. Allega istruzioni contestuali per area di prodotto. Definisci i tuoi glossari una volta. Lascia che il layer di caching riduca i costi al crescere dei volumi. Aggiungi la memoria di traduzione in modo che l’output migliori nel tempo. Il risultato è un layer di localizzazione che funziona automaticamente, costa meno per carattere man mano che l’utilizzo cresce e non richiede un umano nel ciclo per intercettare errori terminologici.
Questo è ciò che la traduzione adattiva significa concretamente: non un modello più intelligente, ma uno configurabile. La qualità dell’output riflette la qualità dei parametri che gli porti. Kanpla ha portato buoni parametri. L’API ha consegnato.
Domande frequenti
Cos’è un’API di traduzione adattiva?
Un’API di traduzione adattiva è un servizio di traduzione che accetta parametri configurabili per ogni chiamata — come istruzioni contestuali, preferenze di stile, glossari e memorie di traduzione — e li utilizza per modellare l’output prima di restituire un risultato. A differenza delle API di traduzione automatica standard, che producono un output fisso basato sui default del modello, un’API adattiva si adatta al dominio, al pubblico, alla terminologia e al registro che il developer definisce al momento della richiesta. L’Adaptive Translation API di Lara Translate espone tutti questi controlli via REST, con SDK disponibili in Python, Node.js, PHP e Java. È disponibile un piano gratuito per testare con i tuoi contenuti prima di impegnarti in un piano a pagamento. Consulta la documentazione per sviluppatori per il riferimento completo.
Come il contesto migliora la qualità della traduzione IA?
Il contesto migliora la qualità della traduzione fornendo al modello informazioni che altrimenti dovrebbe indovinare. Senza contesto, un termine come “stamp card” potrebbe essere tradotto come un oggetto fisico piuttosto che come una funzionalità di programma fedeltà. Con un’istruzione contestuale che chiarisce che si tratta di un elemento UI di fedeltà digitale, il modello produce l’output corretto senza alcun post-editing. Il contesto controlla anche registro, formalità e dominio. Passare “pubblico tecnico, documentazione SaaS B2B” produce un output diverso rispetto alla stessa stringa senza istruzione, anche da una sorgente identica. Kanpla ha usato istruzioni contestuali per sezione per eliminare errori di traduzione che prima venivano rilevati solo dopo il deployment. La knowledge base di Lara Translate contiene esempi pratici nella pagina dedicata ai casi d’uso delle istruzioni contestuali.
Qual è la differenza tra memoria di traduzione e glossario?
Un glossario è un elenco di termini che devono essere tradotti in un modo specifico, sempre, senza eccezioni — nomi di prodotto, termini legali, etichette UI dove la coerenza è imprescindibile. Una memoria di traduzione è un archivio di traduzioni approvate a livello di frase che l’API consulta quando incontra contenuti sorgente uguali o simili. I glossari applicano la terminologia a livello di parola; le memorie di traduzione garantiscono la coerenza a livello di frase. Entrambi possono essere allegati alle chiamate API in Lara Translate. Usati insieme, riducono significativamente la deriva su una grande superficie di prodotto multilingue. Consulta come funzionano i glossari in Lara Translate e la documentazione sulla gestione delle memorie di traduzione per i dettagli di configurazione.
Quanto velocemente può un team integrare l’API di Lara Translate?
Kanpla aveva un proof of concept funzionante in due giorni. L’API di Lara Translate è progettata per essere integrata rapidamente, con documentazione chiara, endpoint REST e SDK nei linguaggi server-side più comuni. È disponibile un piano gratuito senza carta di credito, il che significa che puoi eseguire chiamate API reali sui tuoi contenuti prima di qualsiasi impegno commerciale. La guida completa per iniziare è disponibile su developers.laratranslate.com.
L’API di Lara Translate gestisce volumi di traduzione elevati?
Sì. Lara Translate ha elaborato 149,4 milioni di caratteri per Kanpla in una finestra di 90 giorni, funzionando in modo completamente automatizzato senza passaggi di revisione manuale. Ad alti volumi, un layer di caching è fondamentale: Kanpla ne usa uno per memorizzare e riutilizzare le stringhe tradotte, mantenendo la latenza bassa e riducendo significativamente il costo per carattere sui contenuti ripetuti. Per i team con esigenze di volume molto elevate, sono disponibili piani dedicati per agenzie e aziende. Il Piano Team dell’API Lara illustra cosa è incluso al livello team.



